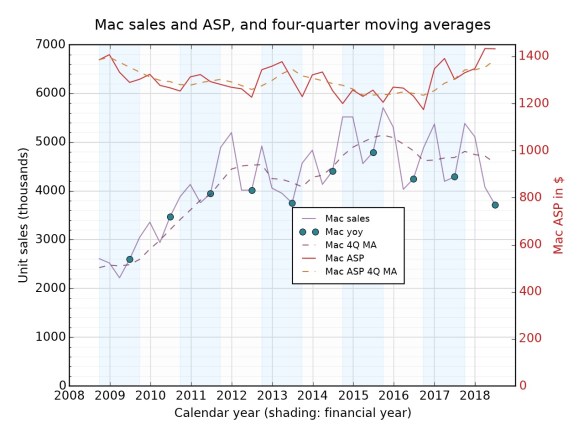
The MacBook Air, in an envelope just like it came in. Photo by yasuhisa yanagi on Flickr.
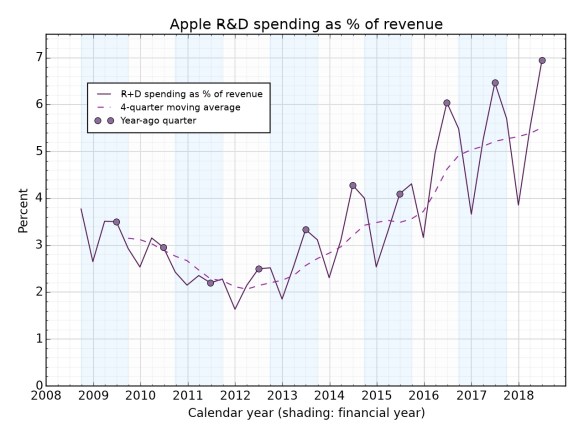
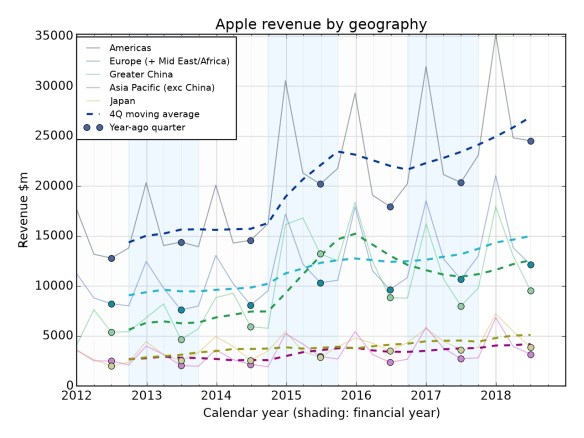
There’s been a lot of discussion about Apple’s HomePod, and the claim from Mark Gurman writing at Bloomberg that it “hasn’t lived up to expectations” in sales terms. Though if you ask analysts in the field, such as Ben Wood of CCS, they thought that 5 million in a year would be impressive. “Clearly my expectations were way lower than others,” commented Ben, which to me has echoes of the vastly inflated numbers that people expected smartwatches, and especially the Apple Watch, to sell, in the first year.
More relevant, I think, is the question of how the HomePod (or just “HomePod” – Apple never uses the definitive for its products, just as a parent wouldn’t for a child) is going to evolve.
And for that, it’s important to bear in mind how every single Apple product tends to evolve: from MVP, aka minimal viable product, to thing that people buy by the million.
Let’s go all the way back to the Bondi Blue iMac, from 1998, since that’s where the story of the modern Apple really begins. This was Apple trying to compete again in the PC market, and choosing to do so in an orthogonal way to pretty much everything else out there. It was all-in-one, it used USB (a new connector at the time), had no floppy drive (this alone was reckoned to spell its doom), and upgrading the RAM and hard drive was difficult.
But the next update showed the trajectory that Apple was on. The Bondi iMac gained colours, and it got more powerful, and added a DVD burner drive if you wanted. It didn’t revert to old connectors, but did add better sound.
iPod, youPod
Next, iPod.

Some of the iPod family – though there were more models and colours than this. Photo by Zengame on Flickr.
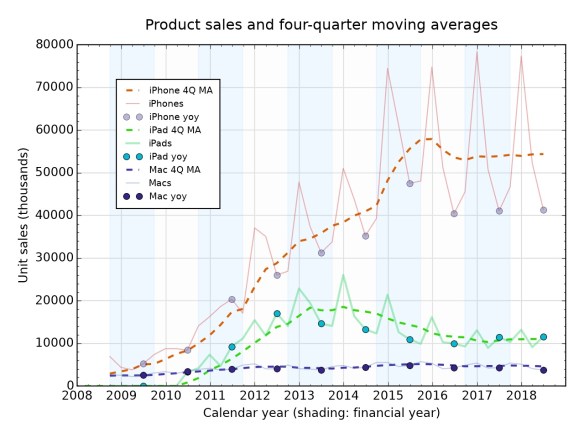
The first one was “expensive”, had a black and white and very pixel-y display, used a proprietary connector, had an unusual yet intuitive method for scrolling through songs, held 1,000 songs. As it evolved through the years, it generated variants that were smaller, had bigger and better screens, more memory, flash memory, but broadly the same controller and interface. (The iPod shuffle is like the Galapagos of iPods, but anyway.)
The MacBook Air (as at the top of the post). The first version had a very limited SSD drive, and underpowered processor. But it had those qualities of being thin and light and offering lots of battery power that people who could afford it really loved – especially when you compared to the average Windows laptop, which weighed tons more, had a DVD drive and floppy drive that road warriors in coffee shops didn’t need, and lasted much less long. You’d still recognise the first model today.
A calling for the iPhone

The iPhone X doesn’t look that different from the 6S, which doesn’t look that different from the original. Photo by Lucy Takakura on Flickr.
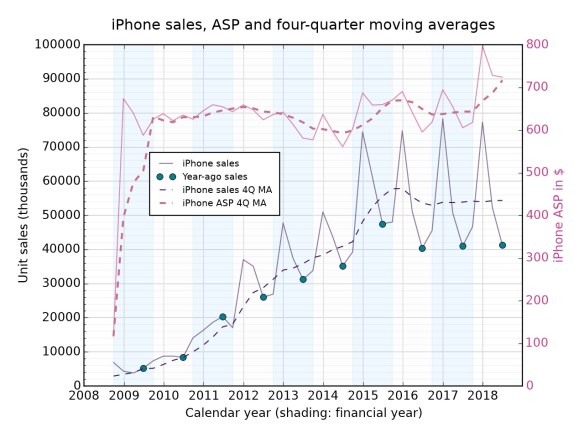
The iPhone is probably the poster child for MVP-ness. The first version’s software was limited (no MMS; no 3G; no text forwarding; no copy/paste), it was really expensive, its battery lasted a day when rival phones could last a week. But it could do so many things that others couldn’t, because of that touch screen and the concept of being a computer for your pocket, not a phone for your email. Subsequent versions have improved along pretty much every axis possible, apart from that battery life stuff (though the iPhone X is a big advance here).
The iPad. Look at these varieties.

iPad sizes have changed, but you’d still recognise the original if you’d only seen the newest, eight years on. Photo by MakeUseOf on Flickr.
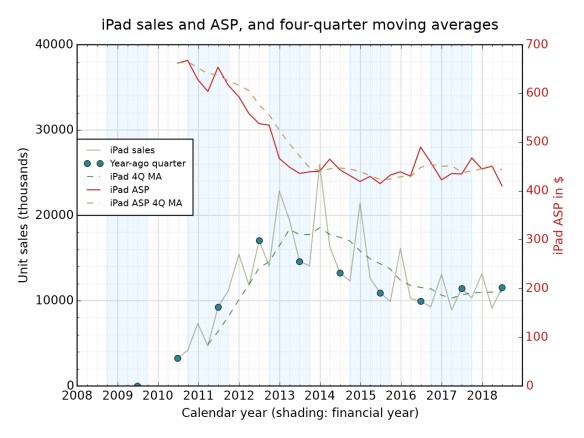
The first version arrived in early 2010 and didn’t have a Retina screen (the iPhone 4, to be released later that year, would; but Retina screens at the size of an iPad were too expensive to contemplate for some time. What it did offer was something that wasn’t a PC trying to be squashed into a tablet form (which Dell and many others had been trying since 2001) and an approach to a big touch-driven screen that harked back to Jeff Haan’s remarkable TED demo of 2005. Since then, its screen has improved (hugely), it has gained an optional keyboard and pencil, and processor power has risen exponentially. But eight years on, the old and new look completely like siblings.
The Apple Watch. The first version could just about take you through a day if you didn’t exercise for too long. There has been plenty of tinkering with how the interface between apps works, but none with the basic concept of how you interact: lift-to-wake, or touches. The addition of GPS and phone data/calling has been welcomed, but if you hold the original Series 0 beside the latest Series 3, it’s essentially still the same thing: a device which hands off tasks from your phone to your wrist.
Bearing all this in mind, what should we expect from the HomePod’s evolution?
Again, look backward first. Look at the axes on which the previous devices evolved.
iMac:
Evolution: colour, extras, price, screen resolution, interfaces.
No evolution: size, shape.
iPod:
Evolution: colour, size, shape, control system, price, screen (colour-capable, video display-capable), output (to TV), interface (from proprietary Firewire, to 30-pin-Firewire and 30-pin USB, to Lightning; and Wi-Fi/Bluetooth in the iPod Touch), processor power.
No evolution: actually, pretty much everything about the iPod changed. (You could however argue that the iPod Touch is actually a cut-down iPhone, not an iPod, and that iPod evolution ended with the iPod shuffle of 2010 and iPod nano of 2012 – the latter being what some thought could be a precursor of an Apple wearable.)
MacBook Air:
Evolution: processor speed, screen size (smaller, never bigger than 13in), weight (reduced), disk size, price.
No evolution: screen quality (after all these years still isn’t Retina), shape, colour (there’s never been a black or rose gold MacBook Air; you want one, it’s aluminium).
iPhone:
Evolution: processor speed (duh), thickness, price, weight, colour, screen size, screen quality, login interface (from passcode to TouchID to FaceID), location capability (GPS, added in 2009’s iPhone 3GS), cameras (front-facing camera arrived on 2010’s iPhone 4).
No evolution: number of buttons (until the iPhone X, which removed the Home button), general interface, general portability, battery life
iPad:
Evolution: size, colour, processor speed, screen resolution, screen capability (Tru-Tone etc), price, functional accessories (Smart Keyboard, Pencil), interface (USB/30-pin to USB/Lightning).
No evolution: screen size ratio, battery life
Apple Watch:
Evolution: battery life, straps, GPS, 4G connectivity, price (by selling older models at lower prices, rather than having differently priced new models, as happened with the iPhone)
No evolution: screen size
All right. Bearing in mind all the above, how should we expect the HomePod hardware to evolve, and not to evolve?
An evolution before your eyes

A “HomePod evolution” concept. Photo by Martin Hajek on Flickr.
Softly spoken, software
Given the way that everything gains software capability, I expect it will gain the capability to play more services than just Apple Music. The ability to play Spotify (which is, don’t forget, the world’s biggest streaming music service) is an obvious piece of low-hanging fruit if you’re looking to tempt people to buy a better-sounding device. Remember, Apple is into hardware sales; Services may be the thing that it talks up, but hardware is the motor that drives the engine.
In which case, why sell HomePod v1 without Spotify capability? Because the v1 is always the MVP – the minimum viable product. Look at the iPhone. Look at the iPad. Look at the MacBook Air. Look at the Apple Watch. They all started out lacking capabilities that seemed obvious (the first iPad didn’t even have alarms, which the iPhone did) and then gained them. Apple has been circling around what the HomePod should do for years – it’s been in development since Siri came on board – and the fact that it took this long to get out of the design labs suggests the usual cautious approach. The people who have bought the first model are obviously, self-definingly, going to be people who like Apple stuff; it can’t, therefore, do any harm to only offer Apple Music as a music service. But putting Spotify on? That’s just a question of an API to Spotify, and an instruction set for Siri so it recognises “play X on Spotify” or “play the X playlist from Spotify”. It can probably be done through a software update.
Other software? Besides playing music, smart speakers’ utility seems to lie in (1) checking the weather forecast (2) setting kitchen timers (3) streaming music (4) setting alarms. Below that, the proportion of people who say they’ve ever done this stuff falls below 50% of smart speaker owners (per Comscore) and it’s hard to know how often people do it.
So – weather, timers, music, alarms. Dig down to the 30% level and there’s also home automation, product ordering (that’s going to be Amazon), calendars, and games/jokes/general questions. (The HomePod can also do iMessage sending and receiving, and FaceTime alls; those don’t come up in the “things people do” listing above 13%, but it’s not something you imagine people wanting to do a great deal.)
These are all things that you can do now. So when people complain about the HomePod’s capability, they’re really complaining that it doesn’t have other music services, and about Siri. The first is a software update, and the second is – well, Apple seems to be working on it.
Hard wearing, but what hardware?
What about hardware? What can we expect there? Is the HomePod more like the portable iPod, which had multiple axes of evolution, or the deskbound iMac? In truth, it might be even closer to a device which I didn’t mention in the list above: the Apple TV.
Like the ATV, the HomePod has a limited interface (via a remote, or by voice), and in general once put somewhere it stays there essentially forever. The ATV has hardly evolved at all – there are a couple of varieties (4K/not 4K) and storage variants, but its onscreen interface is unlike anything else that Apple does. That’s been forced by the limitations of interactions with a TV screen, which one typically views from across a room, and that seems to have limited what it can do.
There has been no evolution of size or colour, and little on price (aside from selling the older model at lower cost). The competition from lower-priced rivals such as Roku, Google’s Chromecast and Amazon’s Fire Stick seems to have kept Apple stuck upmarket, and guarding its content (TV and movies bought on iTunes) jealously: you can’t get them on any of those three rivals without some DRM-fighting shenanigans.
There are signs of the HomePod taking up the same position. You can’t stream Apple Music on the Echo (though Amazon says it’s “open” to it) or Google Home. It’s possible Apple is going to treat the smart speaker market as being like the TV set-top box market – one to be fought over rigidly. Possibly that’s what caused the delay in its initial release: big internal fights over its future trajectory, for these things are all mapped out a couple of years ahead before the first product gets out of the door. (For example, iPhones are designed at least two years ahead.)
But I think that to make the HomePod as “closed” as the Apple TV would be a mistake, and given the way that other successful Apple products have evolved – different shapes and sizes and price points (to fit in with the way that people live their lives), greater software capability (to make the product indispensable, not just nice to have) – I’d expect to see more colours of HomePod, and lower-priced ones too.
It took Sonos years to diverge from its high-end music amps down to the Sonos One, but it’s the latter that was the hit because it found the sweet spot on price. The HomePod is more versatile than the Apple TV because it has more functions than just displaying content on a screen. It’s a voice-driven speaker, and that has lots of implications.
Conclusion
So that’s my thinking: adding Spotify is an open goal, HomePod 2 is a certainty, and we could see smaller HomePods in time if Apple decides that this is a market which is worth winning, rather than just taking part in (the latter being its approach with the Apple TV).
But the early sales numbers? They don’t tell us a lot. Because to lean on those as telling the story means to ignore the ironclad rule of Apple products: the first is the MVP. It’s the ones after that which tell you the trajectory of the device.

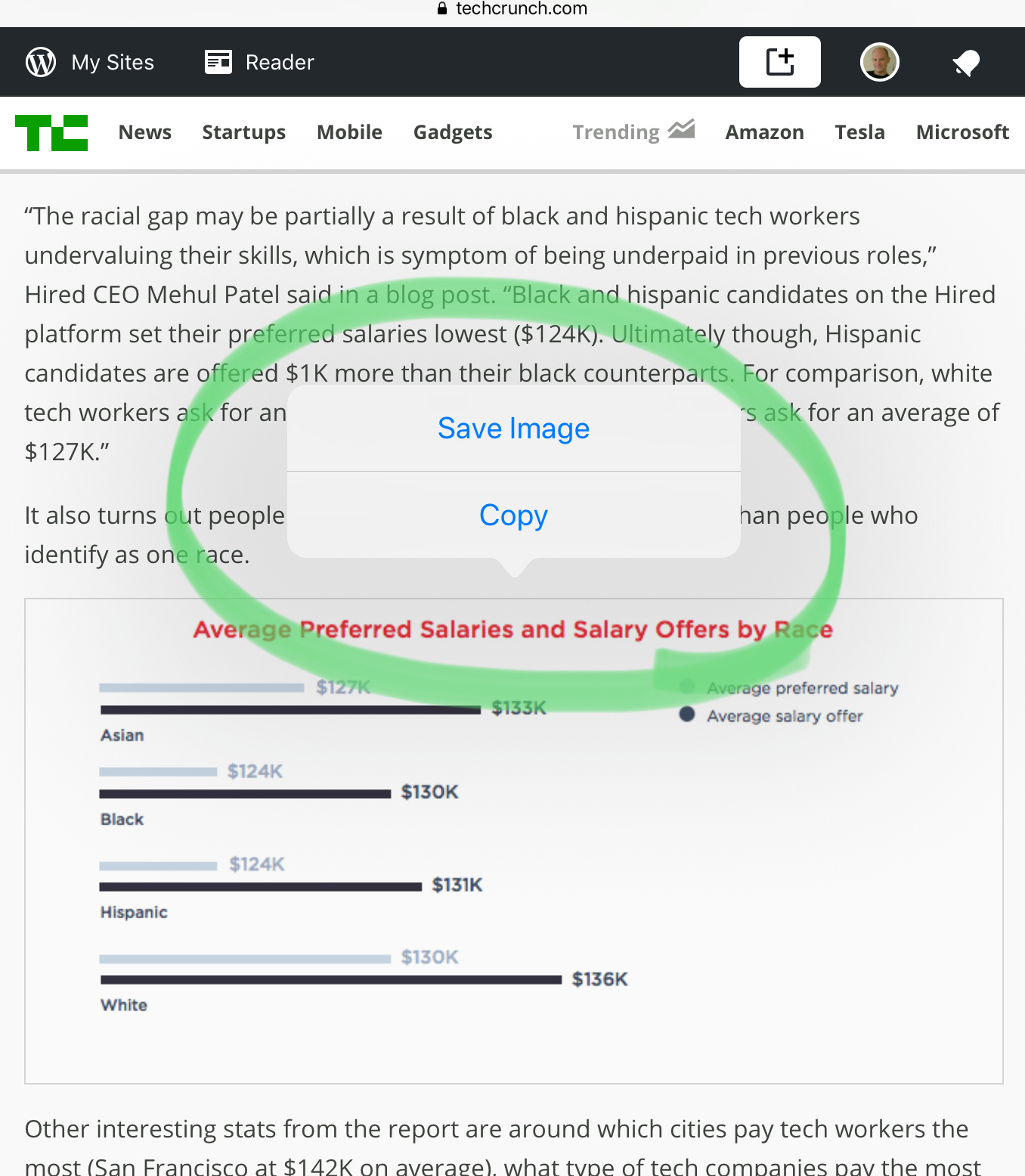
 /
/