

A court case over Andy Warhol’s depiction of a photo of the musician Prince could become a copyright nightmare. (This isn’t it; it’s Stable Diffusion’s output for how a Warhol picture of Prince might look. Which is another copyright question altogether.)
You can sign up to receive each day’s Start Up post by email. You’ll need to click a confirmation link, so no spam.
There’s another post coming this week at the Social Warming Substack on Friday at about 0845 UK time. Free signup.
A selection of 9 links for you. No hot ashes. I’m @charlesarthur on Twitter. Observations and links welcome.
Nuclear fusion plant to be built at West Burton A power station • BBC News
Tony Roe and Alex Smith:
»
A power station has been chosen to be the site of the UK’s, and potentially the world’s, first prototype commercial nuclear fusion reactor.
Fusion is a potential source of almost limitless clean energy but is currently only carried out in experiments.
The government had shortlisted five sites but has picked the West Burton A plant in Nottinghamshire.
The plant should be operational by the early 2040s, a UK Atomic Energy Authority (UKAEA) spokesman has said. The government had pledged more than £220m for the STEP (Spherical Tokamak for Energy Production) programme, led by the UKAEA.
… Business Secretary Jacob Rees-Mogg announced the government’s choice in a speech at the Conservative Party conference in Birmingham.
“Over the decades we have established ourselves as pioneers in fusion science and as a country our capabilities to surmount these obstacles is unparalleled, and I am delighted to make an announcement of a vital step in that mission,” he said. “The plant will be the first of its kind, built by 2040 and capable of putting energy on the grid, and in doing so will prove the commercial viability of fusion energy to the world.”
«
Built by 2040? Can believe it. *Capable* of putting energy on the grid? Can believe it. (Solar arrays are capable of it, and frequently do.) Prove the commercial viability of fusion energy to the world? I think I’ll see an edible hat if that happens.
Hilariously, this is the same location where the local MP and a group of NIMBYs on Friday celebrated blocking a big new solar array, to be located in some nearby fields, which could have been ready in about a year. Wonder how they’ll feel about all the construction traffic that this will involve for a decade or so. Oh well, only swapping one proven fusion source for another, less proven, one.
unique link to this extract
After Ukraine, the great clean energy acceleration • Bloomberg New Energy Futures
Michael Liebreich:
»
according to Brussels-based think tank Breugel, by the middle of September European governments had committed €500bn ($480bn) to keeping the lights on. And this may be just a start: Norway’s energy major Equinor has warned that European energy market participants might need $1.5 trillion in liquidity guarantees to continue to operate. Clearly, this can only go on for so long before the bond markets exact punishment. A re-run of the European financial crisis of 2011 cannot be ruled out.
Other than spending public money, many of our leaders spent the early months of the crisis arguing for whatever energy technology they had always favored – be that renewables, heat pumps and electric vehicles, hydrogen, fracking or nuclear power. Of course, none of these can be deployed fast enough to make much of a difference over the next two critical winters.
…Germany’s Chancellor may be talking up hydrogen, but his ministries are beavering away, demolishing planning barriers to renewable energy projects and accelerating the electrification of heat and transport. No new natural gas boilers may be installed after 2024. Heat pump installations across 21 of the 27 EU member states have doubled over the last four years and are now growing by 34% per year. Plug-in vehicles account for around 20% of new car registrations in the EU, up from less than 5% three years ago. Europe is not just going cold turkey on Russian energy for a couple of years – it is looking to go clean for good.
«
Encouraging, if we can actually get a hold of what we want to achieve.
unique link to this extract
Copyright infringement in artificial intelligence art • TechnoLlama
Andres Guadamuz:
»
Assuming a lot of the inputs that go into training AI are lawful, then what about the outputs? Could a work that has been generated by an AI trained on existing works infringe copyright?
This is trickier to answer, and it may very well depend on what happens during and after the training, and how the outputs are generated, so we have to look in more detail under the hood at machine learning methods. A big warning first, obviously I’m no ML expert, and while I have been reading a lot of the basic literature for a few years now, my understanding is that of a hobbyist, if I misrepresent the technology it is my own fault, and will be delighted to correct any mistakes. I will of course be over-simplifying some stuff.
…style and a “look and feel” are not copyrightable. Sure, an image could be inspired by an author, and you could recognise a style, but it would be a stretch to say that it infringes copyright. One of the challenges for living authors, but also for others whose work may still be under copyright (Warhol and Basquiat come to mind), is that we don’t know if the AIs have been trained on their own artwork, or if they have been trained on the army of human imitators that are all over the web. There’s a reason why the AIs are so good at replicating Van Gogh’s style.
…I am sure that at some point an artist will try to sue one of the companies working in this area for copyright infringement. Assuming that the input phase is fine and the datasets used are legitimate, then most infringement lawsuits may end up taking place in the output phase. And it is here that I do not think that there will be substantive reproduction to warrant copyright infringement. On the contrary, the technology itself is encoded to try to avoid such a direct infringement from happening.
«
I am also not a lawyer, but this seems solidly argued, and it’s what I’ve thought too. So it must be right! 😬 (Thanks Wendy G for the link.)
unique link to this extract
The Andy Warhol case that could wreck American art • The Atlantic
Paul Szynol:
»
[Photographer Lynn] Goldsmith’s prolific and historically significant output has deservedly been archived in various institutions. One of her images was also enshrined by Andy Warhol, who used a photograph she took of Prince as the basis for his illustrations of the musician. But at least in some legal and art circles, Goldsmith may end up being remembered not so much for her beautiful photographs, but for her legal dispute with the custodians of Andy Warhol’s art, which the Supreme Court will hear on October 12.
The dispute started when Goldsmith learned that her 1981 photograph of Prince, which she’d taken in a quick session in her New York studio, was the basis for Warhol’s illustrations of the rock star. In 2019, the United States District Court for the Southern District of New York ruled that Warhol’s image was protected by fair use. The appellate court reversed, principally on the grounds that Warhol’s image is not sufficiently transformative because it “retains the essential elements of its source material” and Goldsmith’s photograph “remains the recognizable foundation.” In other words, the original is too visibly baked into Warhol’s iteration.
To Goldsmith, the question is one of justice; her website describes her battle as a “crusade,” an impassioned effort to make sure that “copyright law does not become so diluted by the definition of fair use that visual artists lose the rights to their work.” If the Supreme Court agrees with her legal challenge, a doctrine that is central to our freedom of expression and cultural growth will be damaged and weakened, possibly for decades to come.
«
Absorbing read about the argument over how far you can derive content. Which is of course relevant to the question of what AI illustration systems can and cannot do.
unique link to this extract
Kim Kardashian paying $1.26m to settle SEC crypto-hype charges • Variety
Todd Spangler:
»
Kim Kardashian agreed to pay $1.26m to settle charges by the Securities and Exchange Commission that she touted a crypto asset security without disclosing the payment she received for the promotion, the agency said.
Under the settlement, without “admitting or denying the SEC’s findings,” Kardashian also agreed to not promote any crypto asset securities for three years, per the agency.
According to the SEC’s order, Kardashian failed to disclose that she was paid $250,000 to publish a post on her Instagram account about EMAX tokens, the crypto asset security being offered by EthereumMax. Kardashian’s post linked to the EthereumMax website, which provided instructions for potential investors to purchase EMAX tokens.
Kardashian, a celebrity reality-TV star and influencer, has one of the most-followed accounts on Instagram — currently with 301 million followers.
“This case is a reminder that, when celebrities or influencers endorse investment opportunities, including crypto asset securities, it doesn’t mean that those investment products are right for all investors,” SEC chairperson Gary Gensler said in a statement. “Ms. Kardashian’s case also serves as a reminder to celebrities and others that the law requires them to disclose to the public when and how much they are paid to promote investing in securities.”
…Kardashian’s agreed payment of $1.26m includes approximately $260,000 in disgorgement (which represents her promotional payment plus prejudgment interest) and a $1m penalty.
«
I hope this chart from Coinmarketcap gives some insight into how this all panned out. You may be able to see the point at which Kardashian’s post appeared.
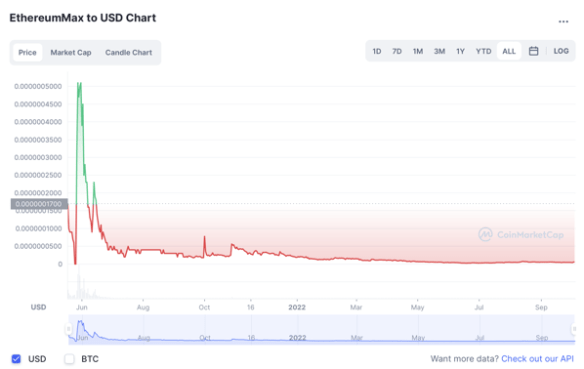
unique link to this extract
Elon Musk may have a point about bots on Twitter • RAND
Marek Posard is a military sociologist (?) and professor at Pardee RAND Graduate School:
»
Twitter has a deep bench of engineers working for the company. They have access to trillions of data points on their over 300 million monthly active users. Why has a company this size struggled to clean up its platform?
Back in 2020, I led a project at RAND that developed tools to detect Russian interference in US elections on Twitter. Our team was small (fewer than 10 people). We had access to only 2.2 million tweets from 630,391 unique accounts. In a few months, our team was able to detect patterns of Russian bots and trolls on the platform that appeared to be interfering with American elections. If RAND could pull this off in a few months, why couldn’t Twitter do the same on a larger scale?
Here’s a possible hypothesis: Twitter might not want to look too closely at this problem because then they would have to remove accounts, reducing the number of reported “active users” on the platform.
More than 90% of Twitter’s revenue comes from advertisers. And it is probably safe to assume that most of these advertisers are paying Twitter to display ads to real human beings, not bots or Russian trolls masquerading as Americans. If Twitter removed more of these inauthentic accounts, it would ding its “active user” metrics, which drive advertising revenue—the source of value for the platform.
Twitter is not the only social media with this problem. Back in 2017, Facebook claimed that ads on its platforms could reach 41 million Americans between the ages of 18 and 24 years old. The problem was the US Census Bureau claimed that only 31 million Americans in this age group existed. Facebook is now facing a class-action lawsuit related to audience exaggeration.
Put simply, social media companies like Twitter and Facebook are not incentivized to look too closely at the problem of bots, trolls, and inauthentic accounts. The latest whistleblower, Peiter “Mudge” Zatsko, who used to be head of security at Twitter has said as much.
«
I think Twitter’s argument, repeatedly made, is that only 5-10% of those it counts as “daily active users” are bots. Not that only 10% of the whole user base is. And Russian bots trying to influence an election are much easier to spot than most. And, again, what is a bot? What’s the dividing line?
unique link to this extract
Russians dodging mobilization behind flourishing scam market • Bleeping Computer
Bill Toulas:
»
Another interesting trend that arose from the widescale exit of Russians is a 50% rise in the demand for the so-called “gray” SIM cards, reported by Russian news outlet Kommersant.
These are SIMs that people can get without presenting an identity document or registering their real subscriber information to the telecommunication service providers. Kommersant’s source stated that these SIM cards work in the networks of MTS, MegaFon, Beeline, Tele2, and Yota, and concern “pay-as-you-use” programs.
Russians are frantically seeking these cards because the state can use regular SIMs to track young men eligible for military service and possibly stop them at the border.
All this has led to the Russian border officers now tracking people based on their IMEI (International Mobile Equipment Identity), a unique 15-digit identifier linked to the device’s hardware, not the SIM card.
According to the Russian internet rights organization Roskomsvoboda, there are multiple reports of people who FSB agents forced to give away their IMEI numbers while crossing the border to Georgia, Kazakhstan, and Finland.
IMEI tracking works by using telecommunication antennas for approximate location triangulation, and it’s made possible thanks to the mobile operator keeping the number stored in their database. IMEI is included in every data transaction and communication request from and to the device and adjacent antennas, so it’s a persistent identifier. It’s the same system used by tracking software promising to locate your lost or stolen device, while law enforcement has also been using IMEI for many years now.
Assigned IMEIs aren’t interchangeable or editable, except for some Huawei, Xiaomi, and ZTE models that store the IMEI in a rewritable memory section in violation of the technology’s guidelines, giving users the capability to flash it with specialised tools.
«
A follow-on from yesterday’s link about the “unfitness” certificates (which get a mention earlier in the story: they’re often scams, as I suspected). IMEI tracking and the very intriguing detail about *some* Chinese models with rewritable IMEIs. Why do those exist at all? Espionage?
unique link to this extract
Does Apple’s crash detection work? We totaled some cars to find out • WSJ
Joanna Stern:
»
Here’s how I set up the tech inside the vehicles for this not-exactly-scientific test [getting a demolition derby driver, Michael Barabe, to crash into some cars in a junkyard]:
• Derby car: Around Michael’s wrist was an Apple Watch Ultra. Strapped next to him in durable OtterBox cases: an Apple Watch-paired iPhone 14 and a Google Pixel 5. Apple’s crash feature is on by default; on the Pixel, you have to turn it on in the Personal Safety app.
• Junkyard car: Secured to the air vents and also protected by durable cases, an iPhone 14 Pro Max and a Google Pixel 6.
About five seconds after Michael first crashed into the Ford Taurus head-on, at about 25 mph, the Apple Watch Ultra on his wrist buzzed with an alert: “It looks like you’ve been in a crash.”
Michael hit the cancel button on his wrist. Had he not done that within 10 seconds, he would have heard a loud alarm and seen a 10-second countdown. Without further action, the watch would then have called 911 and sent a message with his location to a personal emergency contact.
While the impact barely moved Michael at all, the phones went flying onto the floor of his car. That’s why Apple designed the feature to display the alert on the Watch if it is paired together with an iPhone.
Despite the Taurus’ driver-side air bag going off—and the entire front of the car being smashed in—the iPhone and the Pixel in that car didn’t detect a crash. Nor did the Pixel in Michael’s car.
We tried again. On the second crash, the Taurus’ passenger-side air bag deployed, and the bumper went flying. Again, the phones inside the Taurus didn’t display an alert. Inside Michael’s car, the Pixel detected the crash, but that time the Apple devices didn’t.
«
She tried various other combinations: results were mixed. Apple and Google both said that the systems would want more data to indicate you were driving – the sustained periods at speed. (So the lesson seems to be, don’t have a crash too close to home?)
Also: the story pictured in this tweet suggests that indeed, crash detection does work. A pity that it was needed.
unique link to this extract
How I found a simple, no-cost solution to sleep apnea • Daily Beast
Jay Hancock:
»
I woke up in a strange bedroom with 24 electrodes glued all over my body and a plastic mask attached to a hose covering my face.
The lab technician who watched me all night via video feed told me that I had “wicked sleep apnea” and that it was “central sleep apnea”—a type that originates in the brain and fails to tell the muscles to inhale.
As a journalist—and one terrified by the diagnosis—I set out to do my own research. After a few weeks of sleuthing and interviewing experts, I reached two important conclusions.
First, I had moderate apnea, if that, and it could be treated without the elaborate machines, mouthpieces, or other devices that specialists who had consulted on my care were talking about.
Second, the American health care system has joined with commercial partners to define a medical condition—in this case, sleep apnea—in a way that allows both parties to generate revenue from a multitude of pricey diagnostic studies, equipment sales, and questionable treatments. I was on a conveyor belt.
It all began with a desire for answers: I had been feeling drowsy during the day, and my wife told me I snored. Both can mean obstructive sleep apnea. With obstructive sleep apnea, the mouth and throat relax when a person is unconscious, sometimes blocking or narrowing the airway. That interrupts breathing, as well as sleep. Without treatment, the resulting disruption in oxygen flow might increase the risk of developing certain cardiovascular diseases.
So I contacted a sleep-treatment center, and doctors gave me an at-home test ($365). Two weeks later, they told me I had “high-moderate” sleep apnea and needed to acquire a continuous positive airway pressure, or CPAP, machine, at a cost of about $600.
Though I had hoped to get the equipment and adjust the settings to see what worked best, my doctors said I had to come to the sleep lab for an overnight test ($1,900) to have them “titrate” the optimal CPAP air pressure.
“How do you treat central sleep apnea?” I worriedly asked the technician after that first overnight stay. She said something about an ASV (adaptive servo-ventilation) machine ($4,000). And one pricey lab sleepover wasn’t enough, she said. I needed to come back for another.
…recent European studies have shown that standards under the International Classification of Sleep Disorders would doom huge portions of the general population to a sleep apnea diagnosis—whether or not people had complaints of daytime tiredness or other sleep problems.
A study in the Swiss city of Lausanne showed that 50% of local men and 23% of the women 40 or older were positive for sleep apnea under such criteria.
Such rates of disease are “extraordinarily high,” “astronomical,” and “implausible,” Dr. Dirk Pevernagie, a scientist at Belgium’s Ghent University Hospital, wrote with colleagues two years ago in a comprehensive study in the Journal of Sleep Research.
«
| • Why do social networks drive us a little mad? • Why does angry content seem to dominate what we see? • How much of a role do algorithms play in affecting what we see and do online? • What can we do about it? • Did Facebook have any inkling of what was coming in Myanmar in 2016? Read Social Warming, my latest book, and find answers – and more. |
Errata, corrigenda and ai no corrida: none notified
