
An academic side project for deciding whether Twitter accounts are bots will be a centrepiece in Elon Musk’s claim against buying the company. (Picture: “Bots on Twitter”, generated by Diffusion Bee.)
You can sign up to receive each day’s Start Up post by email. You’ll need to click a confirmation link, so no spam.
It’s Friday, so there’s another post due at the Social Warming Substack at about 0845 UK time.
A selection of 9 links for you. Use them wisely. I’m @charlesarthur on Twitter. Observations and links welcome.
Rohingya seek reparations from Facebook for role in massacre • AP News
Barbara Ortutay:
»
For years, Facebook, now called Meta, pushed the narrative that it was a neutral platform in Myanmar that was misused by malicious people, and that despite its efforts to remove violent and hateful material, it unfortunately fell short. That narrative echoes its response to the role it has played in other conflicts around the world, whether the 2020 election in the U.S. or hate speech in India.
But a new and comprehensive report by Amnesty International states that Facebook’s preferred narrative is false. The platform, Amnesty says, wasn’t merely a passive site with insufficient content moderation. Instead, Meta’s algorithms “proactively amplified and promoted content” on Facebook, which incited violent hatred against the Rohingya beginning as early as 2012.
Despite years of warnings, Amnesty found, the company not only failed to remove violent hate speech and disinformation against the Rohingya, it actively spread and amplified it until it culminated in the 2017 massacre. The timing coincided with the rising popularity of Facebook in Myanmar, where for many people it served as their only connection to the online world. That effectively made Facebook the internet for a vast number of Myanmar’s population.
…“Meta — through its dangerous algorithms and its relentless pursuit of profit — substantially contributed to the serious human rights violations perpetrated against the Rohingya,” the report says.
A spokesperson for Meta declined to answer questions about the Amnesty report.
«
Sure to run and run, but could become an iconic case.
unique link to this extract
Meta’s new text-to-video AI generator is like DALL-E for video • The Verge
James Vincent:
»
A team of machine learning engineers from Facebook’s parent company Meta has unveiled a new system called Make-A-Video. As the name suggests, this AI model allows users to type in a rough description of a scene, and it will generate a short video matching their text. The videos are clearly artificial, with blurred subjects and distorted animation, but still represent a significant development in the field of AI content generation.
“Generative AI research is pushing creative expression forward by giving people tools to quickly and easily create new content,” said Meta in a blog post announcing the work. “With just a few words or lines of text, Make-A-Video can bring imagination to life and create one-of-a-kind videos full of vivid colors and landscapes.”
In a Facebook post, Meta CEO Mark Zuckerberg described the work as “amazing progress,” adding: “It’s much harder to generate video than photos because beyond correctly generating each pixel, the system also has to predict how they’ll change over time.”
The clips are no longer than five seconds and contain no audio but span a huge range of prompts. The best way to judge the model’s performance is to watch its output. Each of the videos below was generated by Make-A-Video and captioned with the prompt used to generate the video. However, it’s also worth noting that each video was provided to The Verge by Meta, which is not currently allowing anyone access to the model. That means the clips could have been cherry-picked to show the system in its best light.
…Meta is not the only institution working on AI video generators. Earlier this year, for example, a group of researchers from Tsinghua University and the Beijing Academy of Artificial Intelligence (BAAI) released their own text-to-video model, named CogVideo (the only other publicly available text-to-video model). You can watch sample output from CogVideo, which is limited in much the same way as Meta’s work.
«
Moving really fast now.
unique link to this extract
AI-generated images, like DALL-E, spark rival brands and controversy • Washington Post
Nitasha Tiku:
»
Abran Maldonado is an AI artist and a community liaison for OpenAI. On a recent Friday, he sat at his home office in New Jersey and showed off images for an upcoming DALL-E art show. Then he took my request for a text prompt: “Protesters outside the Capitol building on January 6, 2021, AP style” — a reference to the newswire service, the Associated Press.
“Oh my god, you’re gonna get me fired,” he said, with a nervous laugh.
DALL-E spun up four versions of the request. Three of the images were immediately unconvincing: The protesters’ faces were warped, and the writing on their signs looked like chicken scratch. But the fourth image was different. A zoomed-out view of the East Front of the U.S. Capitol, the AI-created image showed a crowd of protesters, their faces turned away.
On closer inspection, telltale distortions jump out, like the unevenly spaced columns at the top of the stairs. But on first glance, it could pass for an actual news photo of a charged crowd. Maldonado marveled at the AI’s ability to fill in little details that enhance the fake version of a familiar scene. “Look at all the red hats,” he said.
…Late one night in July, some of Midjourney’s users on Discord were trying to test the limits of the filters and the model’s creativity. Images scrolled past for “dark sea with unknown sea creatures 4k realistic,” as well as “human male and human woman breeding.” My own request, “terrorist,” turned up illustrations of four Middle Eastern men with turbans and beards.
Midjourney had been used to generate images on school shootings, gore, and war photos, according to the Discord channel and Reddit group. In mid-July, one commenter wrote, “I ran into straight up child porn today and reported in support and they fixed it. I will be forever scarred by that. It even made it to the community feed. Guy had dozens more in his profile.”
Holz said violent and exploitative requests are not indicative of Midjourney and that there have been relatively few incidents given the millions of users. The company has 40 moderators, some of whom are paid, and has added more filters. “It’s an adversarial environment, like all social media and chat systems and the internet,” he said.
«
AI is probably using your images and it’s not easy to opt out • Vice
Chloe Xiang:
»
Viral image-generating AI tools like DALL-E and Stable Diffusion are powered by massive datasets of images that are scraped from the internet, and if one of those images is of you, there’s no easy way to opt out, even if you never explicitly agreed to have it posted online.
In one stark example of how sensitive images can end up powering these AI tools, a user found a medical image in the LAION dataset, which was used to train Stable Diffusion and Google’s Imagen.
On the LAION Discord channel, a user expressed their concern for their friend, who found herself in the dataset through Have I Been Trained, a site that allows people to search the dataset. The person whose photo was found in the dataset said that a doctor photographed them nearly 10 years ago as part of clinical documentation and shared written proof that she only gave consent to her doctor to have the image, not share it. Somehow, the image ended up online and in the dataset anyway.
When the user asked who they would need to contact to have it removed, Romain Beaumont, one of the developers of the LAION dataset and a machine learning engineer at Google according to his Linkedin profile, said “The best way to remove an image from the internet is to ask for the hosting website to stop hosting it. We are not hosting any of these images.” When asked if he has a list of places the image is hosted, he responded, “Yes that’s what the dataset is. If you download it you get the full list of urls. On clip-retrieval demo or similar websites you can press right click see url to see the website.”
…it is clear that, in LAION’s case at least, developers on the project have not sufficiently grappled with why people may not want their images scraped by a massive AI and do not realize how difficult it can be to get nonconsensually-uploaded images removed from the internet. LAION pitches itself as “TRULY OPEN AI.,” an open-source project that is being developed transparently that anyone can follow, contribute to, or weigh in on. And yet, when the project is criticized for privacy invasions, the open-source project has dealt with it by deleting Discord messages and suggesting journalists should not read its open Discord.
«
If it’s on the scrapable web, it’s not a privacy invasion. If it’s used for machine training, it’s not invading your privacy. (If the image is retained, that’s different.)
This student’s side project will help decide Musk vs. Twitter • WIRED
Morgan Meaker:
»
August 5th was not a normal day for Kaicheng Yang. It was the day after a US court published Elon Musk’s argument on why he should no longer have to buy Twitter. And Yang, a PhD student at Indiana University, was shocked to discover that his bot detection software was at the center of a titanic legal battle.
Twitter sued Musk in July, after the Tesla CEO tried to retract his $44bn offer to buy the platform. Musk, in turn, filed a countersuit accusing the social network of misrepresenting the numbers of fake accounts on the platform. Twitter has long maintained that spam bots represent less than 5% of its total number of “monetizable” users—or users that can see ads.
According to legal documents, Yang’s Botometer, a free tool that claims it can identify how likely a Twitter account is to be a bot, has been critical in helping Team Musk prove that figure is not true. “Contrary to Twitter’s representations that its business was minimally affected by false or spam accounts, the Musk Parties’ preliminary estimates show otherwise,” says Musk’s counterclaim.
But telling the difference between humans and bots is harder than it sounds, and one researcher has accused Botometer of “pseudoscience” for making it look easy. Twitter has been quick to point out that Musk used a tool with a history of making mistakes. In its legal filings, the platform reminded the court that Botometer defined Musk himself as likely to be bot earlier this year.
…Botometer is a supervised machine learning tool, which means it has been taught to separate bots from humans on its own. Yang says Botometer differentiates bots from humans by looking at more than 1,000 details associated with a single Twitter account—such as its name, profile picture, followers, and ratio of tweets to retweets—before giving it a score between zero and five. “The higher the score means it’s more likely to be a bot, the lower score means it’s more likely to be a human,” says Yang. “If an account has a score of 4.5, it means it’s really likely to be a bot. But if it’s 1.2, it’s more likely to be a human.”
Crucially, however, Botometer does not give users a threshold, a definitive number that defines all accounts with higher scores as bots. Yang says the tool should not be used at all to decide whether individual accounts or groups of accounts are bots.
«
Still waiting for Musk to have a worthwhile piece of supporting evidence. (I score 0.3, so only slightly bionic.)
unique link to this extract
The sun has won, pt 1: market inevitabilities in electricity production • Planetary Tech
Rob Carlson:
»
Solar power now provides the lowest cost electricity generation in history. The continuing decrease in solar costs is driven by technological change, economies of scale, and by learning effects derived from the expansion of manufacturing. This cost trend is coupled to an annual exponential increase in solar installation that has run for more than 25 years and that is likely to continue, if not accelerate. Falling costs for solar power are accompanied by a long-term shift in the structure of investment; in 2021 more money was invested on an annual basis into renewables projects than into fossil fuel projects, more new solar power was built than any other generating capacity, and the cost of capital for solar projects was at least 4X lower than for fossil fuel projects. As a result, new solar installation now constitutes more capital-efficient electricity generation than any other source with the exception of wind, which is economically and physically efficient only when installed at very large scales.
…by approximately 2025, operating the vast majority of existing fossil fuel power production will be inefficient and uncompetitive when compared to the combination of new solar power and battery storage.
«
And here’s the graphic for how solar (and wind) have taken over:
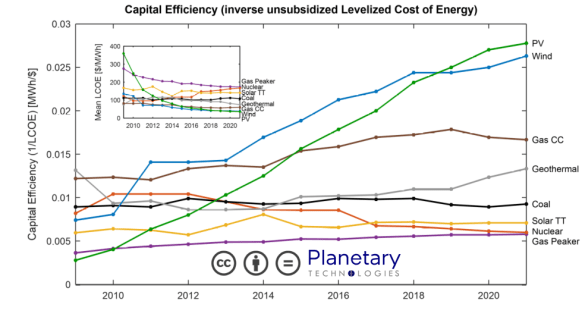
There’s a full PDF with a report.
unique link to this extract
China’s Big Fund corruption probe casts shadow over chip sector • Financial Times
Edward White and Quaner Liu:
»
The sudden disappearance in July last year of Gao Songtao, the bespectacled former vice-president of government fund manager Sino IC Capital, was a warning of a coming storm.
Months later, the Chinese Communist party’s internal watchdog confirmed that Gao had been under investigation for corruption. Yet it was not President Xi Jinping’s public campaign to eliminate graft from financial markets that was behind the detention.
Instead, the deeply feared and highly secretive Central Commission for Discipline Inspection had been running a different operation. The target: China’s massive semiconductor sector and what has been happening to the tens of billions of dollars raised to invest in it.
Gao was one of the first executives to face corruption allegations in a CCDI crackdown that has sent a chill through the sector. In the process, it has highlighted the heavy-handed role of the state, which some analysts believe has laid the groundwork for graft and wasteful spending to flourish and has delivered a setback to China’s aim of achieving self-sufficiency in chips.
“The anti-corruption campaign is a warning to me and my team,” said a senior official at a local government semiconductor fund in southern China. Corruption had been “nurtured” by civil servants who “do not understand the industry”, they said.
«
Given there’s $47bn (equivalent) in that fund, perhaps it’s not surprising that some of it would go walkabout. As has also happened to 12 people involved with it. China’s big leap into chips might be forestalled.
unique link to this extract
Bitcoin-sterling volumes spike to record high as British currency flounders • Reuters
Elizabeth Howcroft:
»
Trading volumes between the British pound and the cryptocurrency bitcoin spiked to a record high after sterling dropped on Monday, according to market data firm Kaiko Research, in what analysts said was likely a rush by investors to dump their sterling for the digital asset or profit from arbitrage.
The pound fell to a record low against the dollar on Monday, having plunged the previous Friday after the UK government announced unfunded tax cuts.
The volume of transactions in the bitcoin-sterling trading pair across eight major exchanges globally spiked to a record high of £846m ($920m) on Monday, according to Kaiko Research, compared with an average of around £54.1 a day so far in 2022.
The surge was likely due to traders swapping sterling for bitcoin, said James Butterfill, head of research at crypto firm CoinShares. “There is a high correlation to bitcoin volume growth and political/monetary instability,” he said.
Butterfill said spikes have previously occurred in other currencies’ crypto trading volumes, such as the Russian ruble and Ukrainian hryvnia, but that he had never seen such big moves in the bitcoin-sterling pair’s volume.
Conor Ryder, research analyst at Kaiko, said the data suggests cryptocurrency markets reacted to the volatility in fiat currencies. When sterling crashed on Sept. 26, “opportunistic investors rushed to crypto exchanges offering BTC-GBP to try and profit via arbitrage from any mispricing of bitcoin across the major fiat currencies,” he said in emailed comments.
«
Strange if people are dumping sterling to buy bitcoin, because the round trip to dollars (for example) is not going to be any more profitable than just exchanging pounds for dollars. I could believe people who bought bitcoin in dollars would sell them in sterling.
unique link to this extract
The dangers of a headline figure • Status-Q
Quentin Stafford-Fraser:
»
If you believe my Twitter stream, there are a lot of people out there who think that the UK government has capped the energy bills so they can’t pay more than £2,500 this year. This is not at all true. But it’s been reinforced by the Prime Minister’s interviews on various radio stations this morning when she said things like “making sure that nobody is paying fuel bills of more than £2,500”. Either she doesn’t understand it, or she’s not very good at explaining things clearly.
The problem is that the media are so keen to feed people a single, simple number, that for weeks we’ve been hearing about what’s happening to the energy costs for the average household and referring to that as a capped number, when in fact, of course, it’s the price per kWh that’s been capped. (More info here.) If, say, you use twice as much as the average household, your bill could be £5000. Some not-very-smart people even think they can use as much as they like, because, hey, it’s been capped now, and they’re going to get a nasty surprise! And similarly, of course, if you use half as much, you can worry a bit less about that headline figure.
…Now, the headline figure for every electric car is the number of miles it can do on a charge, when lots of other factors will affect how easy it is to use in reality, like how fast it charges, or its drag coefficient (which affects how its energy use varies with speed). For many people, long journeys are relatively rare, and the important question when embarking on one will actually be something like, “How fast will this be able to recharge at the type of chargers available about 150-200 miles from my house?” And even that question is much less important if the chargers happen to have a nice cafe or restaurant next to them!
«
Truss’s appearance on eight different local stations in an hour was a slowly mounting car crash. She started out saying the average would be £2,500 but as she moved on, started saying it was the maximum. If you can’t even keep that in mind, it suggests you don’t actually understand it.
unique link to this extract
| • Why do social networks drive us a little mad? • Why does angry content seem to dominate what we see? • How much of a role do algorithms play in affecting what we see and do online? • What can we do about it? • Did Facebook have any inkling of what was coming in Myanmar in 2016? Read Social Warming, my latest book, and find answers – and more. |
Errata, corrigenda and ai no corrida: none notified

If it’s a violation of human rights to profit from being a propagandistic warmonger, won’t a whole lot of media companies find themselves liable? Is there any international law that truly imposes liability on an uninvolved party (in the armed conflict sense) cheering on a war because it sells papers, err, click-ads? Could, say, a future government of Iraq demand reparations from the New York Times for recklessly negligent coverage leading to the Iraq War?
One of the more intriguing aspects to me of the moral panic over algorithms, is how it functions as way of having the chattering class talk about what’s very much (just being descriptive) an anti-free-speech argument, but insulating themselves from having that argument apply to them. That is, if someone put forth a position arguing it’s necessary to control the media for the good of the whole, since such organizations have intrinsic economic incentives to whip up fear and division, well, that’d be considered rather threatening in the West. And mostly relegated to the fringe of polite (media) society. But make it about the evils of “*tech*bros”, and then it’s a completely different story.